





![]()
1. Introduction
KanjiUp is a mobile applications, helping the user learning or deepening his learning of kanji characters. It has been deployed on the web 🔗, and an APK 🔗 is available for android users. To test the application, you can register as a new user or use this :
{
user: 'demo@kanjiup.me',
password: 'test1234',
}
Kanji (漢字, Japanese pronunciation: [kaɲdʑi]) are the logographic Chinese characters adapted from the Chinese script used in the writing of Japanese (source: Wikipedia 🔗)
Nowadays, with the arrival of the technology like computers, smartphones, etc. the necessity of writing kanji by hand is almost null, which could lead us to believe that it is almost intended for artists like old styled writers and mangaka, calligrapher, etc.
However, knowing how to draw the characters by hand can be very helpful in the learning process. There are lots of characters that look like similar at first glance, but that have slight nuances.
Example: 緑 and 縁 are similar for someone not familiar with kanji characters, but they have completely different meanings, the first one means green while the second one means connection or edge
Knowing how to write it by hand, means that you know how each character is composed, the different patterns possible. It is way more intuitive to learn by drawing them. Even Japanese people learn by drawing the characters multiple times during their education from elementary school to the graduation of high school which the total of kanji learned is 2136 and is the strict minimum to be able to live in Japan, also called the jōyō kanji (常用漢字). For advanced kanji, they can continue to study them after high school at university. In general, it seems that a university graduate can read around 4000 and 5000 kanji characters, but can only write around 300 characters.
Nowadays, there are multiples applications that can help users to learn kanji characters. But it can be very limited on kanji character number available or be accessible by paying extensions.
The purpose of this project is to offer a wide range of kanji characters data (around 13000 out of 40000) and allowing users to challenge themselves with drawing quizzes, which evaluates the number of strokes drawn and its correctness of at least all the jōyō kanji. Ideally, it would check the character's form + the stroke order.
2. Implementation
2.1. Preparation
Create myself the data by hand would not only be time-consuming, it would also be too tedious and repetitive, and I'd give up before I'd even started the project. So I looked for open databases that were both qualitative and quantitative.
2.1.1. Kanji
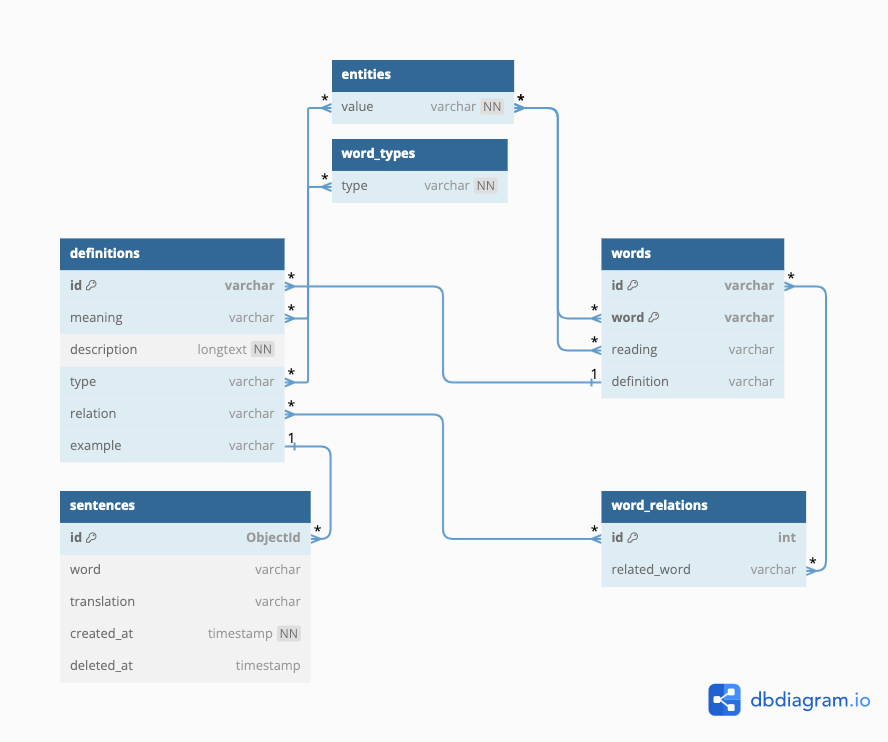
All kanji information come from JMDict, a kanji dictionnary containing 13,108 kanji writen in a XML format and Unicode/UTF-8 coding file. I took all the 13, 108 kanji information and input into a MongoDb database with a script accessible here 🔗. Below, you can find a representation of the collections with their relationship used to input the information on the database:

2.1.2. Word
I did the same for all Japanese word, using JMDict, a Japanese-Multilingual Dictionary also written in a XML like format and Unicode/UTF-8 coding file. The script to input the data into a MongoDB database accessible here 🔗 with a total of 207, 059 words inputted. And below there is the representation of the word's collections:
2.1.3. Handwritten kanji dataset
I could've create an application to draw it myself to create a dataset of at least all the jōyō kanji would take me years to complete it, even if I asked my friends to help me.
So I used ETLDB's ETL9B data to build my dataset, they come in an archive file and with a script 🔗 to extract and split into multiple folders, which are ordered by kanji character. In total 2965 kanji character's folders are created. Each folder contains 200 monochrome pictures, and each picture has a resolution of 64x63.
2.2. Kanji Recognition
2.2.1. Preprocessing
To train my recognition model, I'm using the split-folders library to split the pictures into 3 folders : train, validation and test with a ratio of 80%, 10% and 10% which correspond to 474401, 59293 and 59311 pictures.
- train is the dataset that will train the model
- validation is the dataset that will challenge the model during the training process
- test is the dataset that is not used to train the model, and is used to evaluate the accuracy/loss of the model at the end of the training
.
├── test
│ ├── ...
│ └── 育
├── train
│ ├── ...
│ └── 育
└── validation
├── ...
└── 育

As you can see, all pictures have a black background. If I were to train the model with those data, I would be forced to use a black background in my future application, or invert the colours of each drawing before analysing it (on my application), which would be heavy.
Instead, I've inverted the colours of each pictures during the preprocessing of the generation of batches of tensor image data. As a result, the model is trained on white background's images.
I also want to checked that each image of the batches is associated with the correct label. So I took a sample of 15 images of the train batch and compared it with the corresponding label (Labels are taken from Unix command ls).
 The result seemed to be good, so I continued to the training part
The result seemed to be good, so I continued to the training part
2.2.2. Training
The most common way to train a character recognition model, and classify the drawing images, is the CNN :
Convolutional neural networks (CNNs) are the current state-of-the-art model architecture for image classification tasks. CNNs apply a series of filters to the raw pixel data of an image to extract and learn higher-level features, which the model can then use for classification (source: Tensorflow 🔗)
To train the model, I looked for examples of OCR model's training to see the hyperparameters and combination that would give me the best accuracy. I ended with this configuration using Tensorflow/Keras :
- Convolutional Layer : Applies 32 3x3 filters (extracting 3x3-pixel subregions), with ReLU activation function
- Pooling Layer : Performs max pooling with a 2x2 filter and stride of 2 (which specifies that pooled regions do not overlap)
- Convolutional Layer : Applies 64 3x3 filters, with ReLU activation function
- Pooling Layer : Again, performs max pooling with a 2x2 filter and stride of 2
- Dense Layer : 1,024 neurons, with dropout regularization rate of 0.2 (probability of 0.2 that any given element will be dropped during training)
- Dense Layer (Logits Layer): 2965 neurons, one for each target class
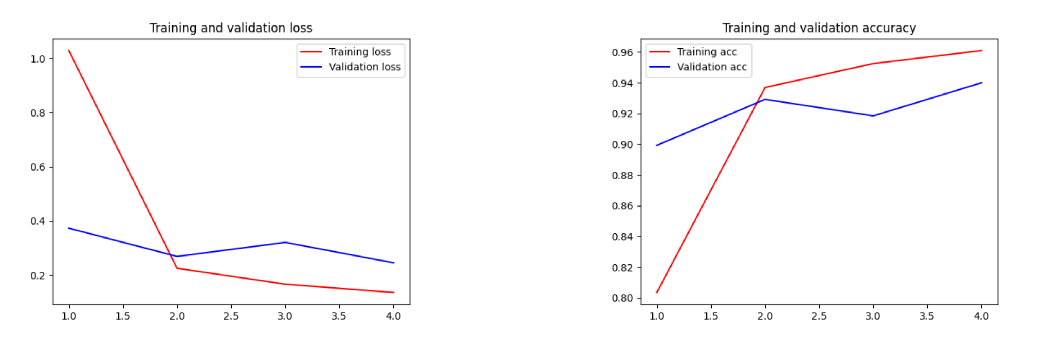
The final accuracy I got was 96.09% with a validation accuracy of 94.43%. It is OK for the moment, but I will try to improve it in the future by playing around with the different parameters and by correcting some images like this :
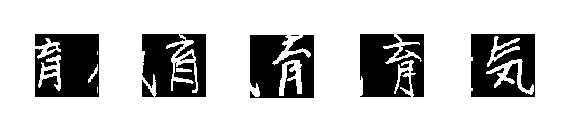
2.3. Application
Now that the recognition model has been created, and the kanji and word's data on the dedicated database. What's left to do is to developed interactive interfaces to be able to watch all the information on kanji characters and words, and be able to practice the knowledges acquired during the learning and not forget it with games, quizzes, etc.
2.3.1. Project structure
At the begining of the project, the MVP only had the kanji details related functionalities and the drawing quizz and the front-end was a React Native monolith application with the data stored locally. But the bigger the project got, the harder it became to manage bugs on the different platforms (web + ios + android).
So with the arrival of a new version of Expo and its new project structure, It was for me the opportunity to change my way of coding it, and I choose to implement this project with micro-frontend and micro-service architectures (picture below).
Microservices are both an architecture and an approach to writing software. With microservices, applications are broken down into their smallest components, independent from each other. Instead of a traditional, monolithic, approach to apps, where everything is built into a single piece, microservices are all separated and work together to accomplish the same tasks. Each of these components, or processes, is a microservice. This approach to software development values granularity, being lightweight, and the ability to share similar process across multiple apps. It is a major component of optimizing application development towards a cloud-native model. (source: RedHat 🔗)
Micro frontend is a front-end web development pattern in which a single application may be built from disparate builds. It is analogous to a microservices approach but for client-side single-page applications written in JavaScript. It is a solution to de-composition and routing for multiple front-end applications. (source: Wikipedia 🔗)
The reasons of this choice was that I wanted to gradually implement the differents functionalities, assure that they were stable before advancing on an other functionality without modifying the old ones, and then for their maintanabilities, but also for my motivation and not have to manage all the functionalities at once and run the risk of having a lot of bugs.
Here is the project architecture at high level, I am aiming for :
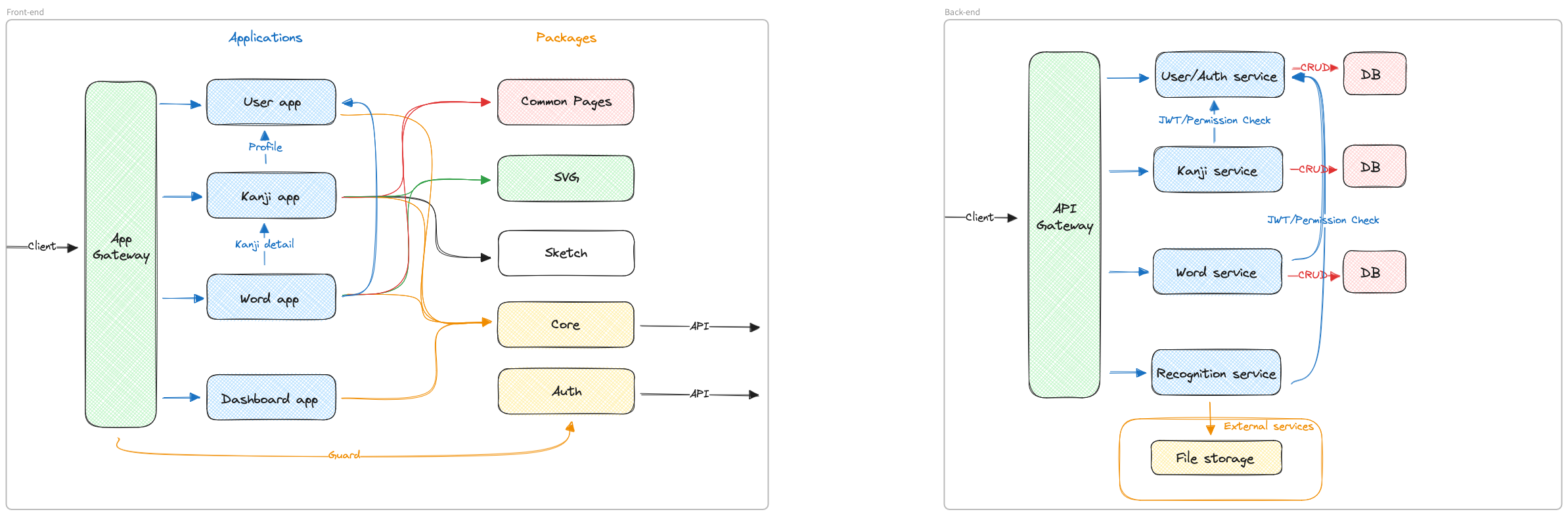
On the left is the front-end architecture designed upon a yarn workspace, allowing to create multiples packages that can be shared between the different applications belonging to the workspace. And on the right is the back-end architecture, containing multiples services with their dedicated database. Each service is independent of each other and can be developed on a different coding language like the recognition service which is coded in Python (FastAPI), for the training and the usage of the recognition's model.
2.3.2. Technologies used
This application is a tool that I wanted to have during my learning, and it allows me to combine two of my passions. So this project is kind of a playground for coding where I can apply all my knowledges, try improving them and where I can try new technologies, new ways of coding, for instance the implementation of the new architecture with the yarn workspace.
So for this project, I am using :
- Node.js, with Express which I am familiar with, allows to develop light back-end app, and it matches the need of the project which is to do CRUD operations on the database
- Nest.js, a Node.js framework which its architecture is inspired by Angular, and allows to structure the code into independent modules that hold components, and then to develop highly testable, scalable, loosely coupled, and easily maintainable applications
- FastAPI, a web framework using Python and allowing me to deploy quickly my recognition model (Tensorflow/Keras)
- React Native with Expo, a framework for develop mobile (web + native) applications. I'm using it because it allows me to have a single code in Typescript, for all the platforms and finally because it can be easily tested on devices with the application Expo Go. I am also using it with Redux that allows me to have a global state to store data like user's info, fetched data, etc. and be able to access it throughout the application
- Next.js, a framework to develop SSR and SSG web applications. I use it for kanji-up dashboard and have an graphic interface to manage easily the app data
- MongoDB, a NoSQL database with mongoose to store data with consistence, and a kind of relationship
- AWS S3, a file storage to store all pictures to train the model or other files like tflite/tfjs models
Each of the back-end services are dockerized and pushed on the docker hub, to be pullable during the creation of each pods on the minikube (local) Kubernetes cluster. For the production cluster, all I will need to add is a certificate manager to generates SSL certification with auto-renewal.
2.3.3. Authentication
The authentication is implemented on server side to be accessible from all applications coded in differents languages, and to be implement it only one time.
Here is the workflow of the authentication :

To automatically login the user, I'm storing the access token (JWT) in cookies and in the session collection to check the validity of the token.
3. Result
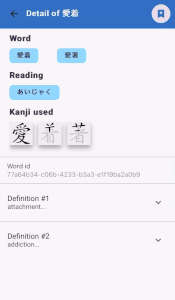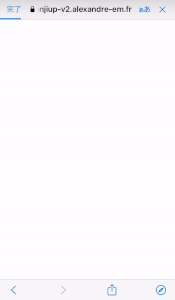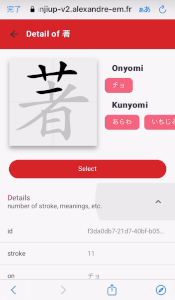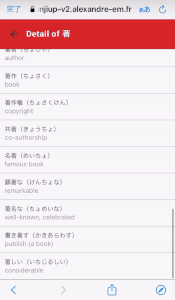
Here is an example of Word application "communicating" with the Kanji-up application, so the user can see the detail of the selected kanji character but he can also select the kanji so it will added to games, quizzes, etc.
4. Conclusion
Resources
- JMdict 🔗 Japanese-Multilingual Dictionary File by the Electronic Dictionary Research and Development Group 🔗, licensed under CC BY-SA 3.0 🔗
- KANJIDIC2 🔗 by the Electronic Dictionary Research and Development Group 🔗, licensed under CC BY-SA 3.0 🔗
- KanjiVG files 🔗 ©2009-2015 Ulrich Apel, licensed under CC BY-SA 3.0
- Kanji Teihitsu 漢字逞筆 🔗, ©2016 はぐん
- ETL Character Database 🔗 by Electrotechnical Laboratory 🔗, Japanese Technical Committee for Optical Character Recognition, ETL Character Database, 1973-1984